detour 211_via Los Angeles
ethniCITY: linguistic landscape data
By: The Spatial Analyses Lab at USC Price
Source/Link:
SLAB on Vimeo, 2019
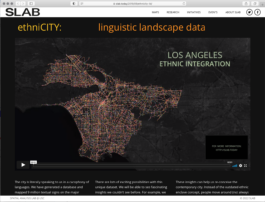
Description: (by author)
The city is literally speaking to us in a cacophony of languages. We have generated a database and mapped 9 million textual signs on the major streets of Los Angeles from 2001/2 and 2017/18 – extracting and geocoding both the words themselves and the languages they speak down to the individual land parcel level. Our database of images, text, location, and date, fills a data gap between public datasets which are perennially outdated and private datasets that often miss small, ethnic establishments. Out error testing reports precision and recall rates of 92%, at the word level.
There are lots of exciting possibilities with this unique dataset. We will be able to see fascinating insights we couldn’t see before. For example, we can now map neighborhoods that have not yet been officially recognized but where communities have been publicly expressing themselves such as Little India, Little Tehran, Little Brazil, etc. Or, instead of focusing on the one official ethnic town such as “Chinatown,” we can now see there are actually 5 much larger “Chinatowns” in the LA region. And we are also finding that instead of only clustering, there are also other geographies such as a network of dispersed nodes for Greek LA. One reason we can do this is because our data is detailed to the individual parcel level, we can aggregate the data into organic clusters that predefined aerial units such as census tracts cannot. Another is because we are capturing all text in the built environment, not just the official names registered and focusing our attention on the commercial and institutional places, instead of residential areas.
These insights can help us re-conceive the contemporary city. Instead of the outdated ethnic enclave concept, people move around (not always by choice) and live urban life dynamically, stitching together geographies of belonging. We see that ethnic places are not singular but overlapping and interspersed. We see signs of true ethnic interaction, with some establishments speaking in four different languages. Stay tuned as we start to generate maps from our dataset!
Back to Text